A native Talos provider for Apple's container runtime
Production dropped the Docker daemon years ago; the local dev loop never did. I tried to close that gap with Talos on Apple's container runtime — and DHCP, then a maintainer's 'no,' turned out to be the real story.

Apple shipped container — an open-source tool that runs Linux containers as lightweight micro-VMs on Apple Silicon. The detail that caught me wasn’t the micro-VMs; it was the contract. apple/container has no Docker API. What it speaks instead is OCI — the Open Container Initiative image standard, the same vendor-neutral format the production world standardized on when it moved off Docker. It consumes and produces OCI images, and nothing Docker-specific.
That mattered because of an asymmetry I’d been chewing on. Production Kubernetes shed the Docker daemon years ago — dockershim is gone, the runtime underneath is containerd or CRI-O, and Talos, the OS I run, ships no Docker at all. But the developer loop never followed: kind, minikube, the Talos docker provisioner all still ride a Docker daemon behind Docker Desktop or OrbStack. Talos ships as an OCI image. apple/container runs OCI images. So I wondered the obvious thing — could the dev loop de-Docker the way prod already did, and run a real local Talos cluster with no Docker daemon anywhere in the stack?
Making it a provisioner, not a one-off, meant implementing Talos’s pkg/provision interface. Go’s structural typing let my out-of-tree implementation compile straight against the real interface, first try — and that “it just compiles” felt like an open door. It wasn’t. Finding out why ran me into the one detail that decides the whole design: how apple/container assigns IP addresses. This is the write-up of that spike — what worked, why a native provider was the only clean path, what the Talos maintainer said when I pitched it upstream, and the lesson I walked into. The code is a public repo; this is the story.
What Apple’s container runtime actually is
container shipped 1.0.0 alongside macOS 26. It is not Docker with a new badge. Each container is a Kata-derived micro-VM — its own Linux kernel (6.18.15 in my runs), its own PID 1, booted by Apple’s vminitd. That is a far stronger isolation boundary than a shared-kernel container — a real bonus for Talos, where each node then behaves like a machine rather than a namespace pretending to be one. But the property that made the experiment possible was the one from the opening: it speaks OCI, the format Talos already ships in.
Apple has been clear they are not building a Docker-compatible API. That single constraint shapes everything downstream. Talos’s talosctl cluster create ships two local provisioners — docker and qemu — and the popular one, the one every tutorial uses, drives the Docker API. With no Docker API to drive, that path is closed. You either emulate the API in front of container, or you teach Talos to talk to container directly.
Two roads, and why the obvious one is a trap
There were two ways forward.
(A) A native provider. Implement Talos’s pkg/provision.Provisioner interface for apple/container. It merges into siderolabs/talos as a new provisioner, the same shape as the docker and qemu ones.
(B) A Docker-API shim. Put a Docker-compatible API in front of container (the socktainer approach), so Talos’s existing --provisioner docker drives it unchanged. Zero Talos changes. Obviously attractive.
I built (A). The deciding factor is a networking detail that looks minor until you trace it through: how apple/container assigns IP addresses.
DHCP is the whole story
apple/container assigns each node’s IP by vmnet DHCP. There is no static-IP option — I checked. That one fact is what breaks the shim.
The Docker provisioner’s contract is static IP, config injected at create. The config maker computes each node’s address up front — .2, .3 — and bakes it into two places that must agree: cluster.controlPlane.endpoint, and the apiserver certificate’s SANs. The provider then creates the container with that IP pinned and passes the whole machine config in as the USERDATA env var. The node is expected to boot already holding the address its config claims.
A shim receiving “create a container at .2 with this USERDATA” cannot honor the IP. DHCP hands out, say, .8. The node boots, etcd and the apiserver bind .8, but the config and the certificate say .2. Nothing matches. The cluster never forms. That is the exact wall the Docker-shim approach hits.
 Top: the shim bakes the IP at create, DHCP overrides it, certs and endpoint disagree, the cluster never forms. Bottom: the native provider owns Create, so it can wait until after boot, read the real DHCP address, and patch the config to match.
Top: the shim bakes the IP at create, DHCP overrides it, certs and endpoint disagree, the cluster never forms. Bottom: the native provider owns Create, so it can wait until after boot, read the real DHCP address, and patch the config to match.
To rescue the shim you would have to intercept the create call, defer the start, discover the DHCP address, and rewrite the base64 USERDATA — but the docker provisioner’s inject-at-create flow leaves no clean seam to do that. The native provider, by contrast, owns Create, so the reconciliation is clean:
- Launch the node bare into maintenance mode — no config yet.
- Read its DHCP address with
container inspect. - Patch
cluster.controlPlane.endpointto that address withconfigpatcher. - Apply the config over the maintenance API.
The Talos framework never changes. The entire DHCP workaround lives inside the provider. That is precisely why the native road works where the shim does not — and it is the one architectural insight that justified the whole spike.
A correction worth making, because I got it wrong early: I first blamed socktainer’s failure on “apple/container has no privileged concept.” That is imprecise.
container run --cap-add ALLis thePrivileged: trueequivalent and it works. The real blocker is the static-IP-at-create contract, not capabilities. Naming the wrong cause cost me a day; naming the right one made the design obvious.
A micro-VM is not a container, and the recipe knows it
Owning Create also meant modelling the micro-VM honestly. Three details bit me before the recipe settled.
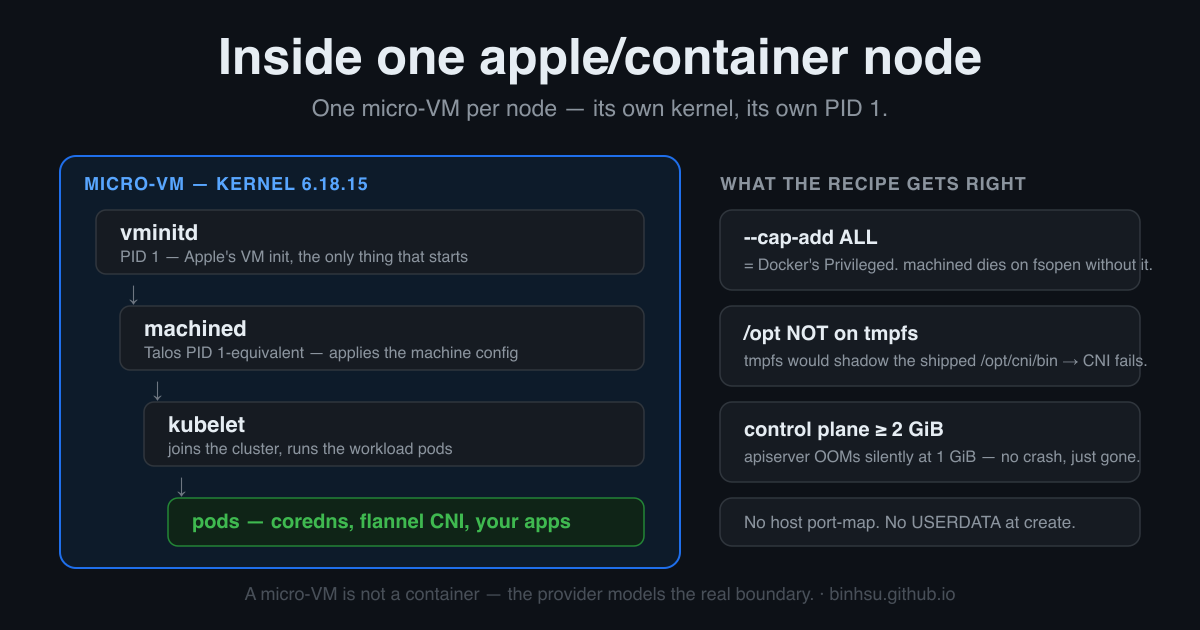 One micro-VM per node: vminitd as PID 1, then machined, then kubelet, then your pods — and the three constraints that took a day each to find.
One micro-VM per node: vminitd as PID 1, then machined, then kubelet, then your pods — and the three constraints that took a day each to find.
--cap-add ALL.machineddies onfsopenwithEPERMwithout it. This is the privileged-equivalent the shim correction above refers to./optmust not be tmpfs. Talos overlays several paths on tmpfs. Do that to/optand you shadow the shipped/opt/cni/bin— the CNI binaries vanish, coredns hangs inContainerCreatingforever. Docker volumes copy-up; tmpfs does not. The fix is to exclude/optfrom the tmpfs set.- The control plane needs ≥ 2 GiB. At 1 GiB the apiserver OOMs silently — no crash log, the process is just gone and the cluster never comes up. The default 2 GiB works.
None of these are in a tutorial. Each was a failed run, a wrong hypothesis, and a correct one.
The payoff: the canonical command, unchanged
The point of doing this as a real provider — not a one-off script — is that the user-facing command is the one every Talos user already knows. No custom driver, no wrapper. You select the provisioner and run:
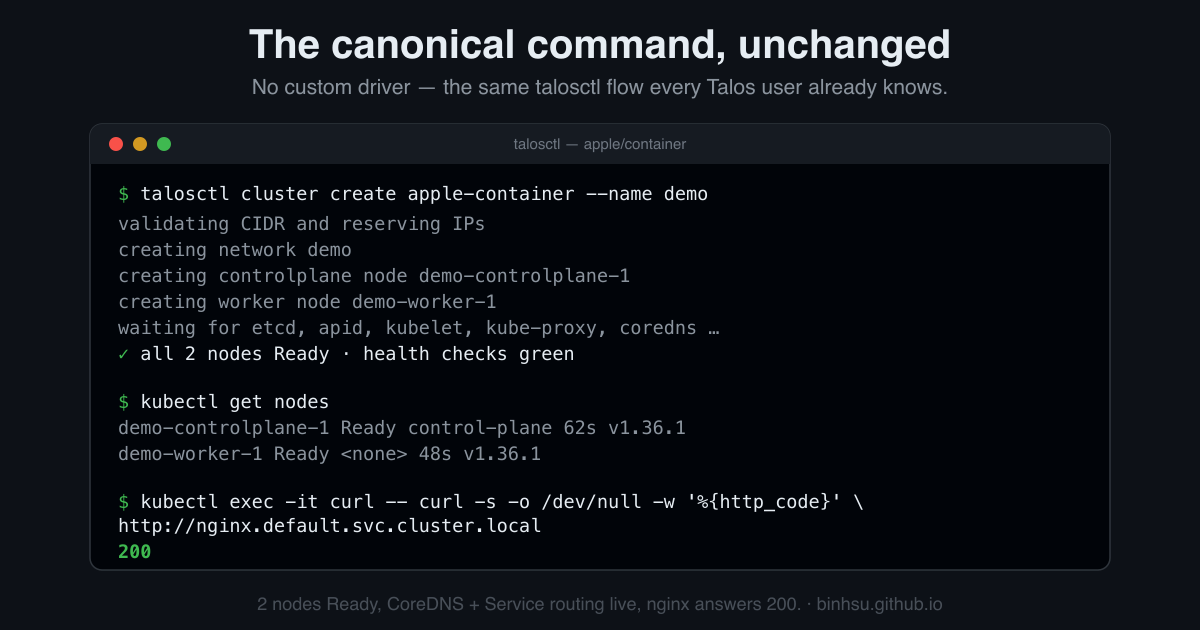 The real flow, end to end: two nodes Ready on v1.36.1, health checks green, and an in-cluster curl to the nginx Service returning 200. CoreDNS, kube-proxy and the CNI are all live.
The real flow, end to end: two nodes Ready on v1.36.1, health checks green, and an in-cluster curl to the nginx Service returning 200. CoreDNS, kube-proxy and the CNI are all live.
I verified it the full distance: talosctl cluster create apple-container brings up a healthy cluster, a canonical nginx Deployment behind a Service answers HTTP 200 from inside the cluster, and teardown is clean. Networking — the part that decides whether this is a toy — holds up too, and here it actually beats the substrate it’s closest to. Talos’s own docs note that under the docker provisioner on a Mac, “VIPs are not supported”; here a MetalLB L2 LoadBalancer VIP is host-reachable — the provider’s vmnet path forwards the gratuitous ARP that the qemu path drops (the #12834 symptom), so the VIP answers from the Mac, not just from inside the cluster. L7 ingress works through the modern Gateway API via Envoy Gateway — which matters, because kubernetes/ingress-nginx was archived in March 2026 and is no longer the answer.
What it doesn’t promise
One honest limit, and it’s the same boundary Talos draws itself. The docs scope the container-mode docker provisioner to “CI pipelines and local testing… not suitable for production deployments,” and note that upgrade, reset, and similar APIs don’t apply in container mode. apple/container inherits exactly that envelope. Concretely: because nodes are micro-VMs with tmpfs root and DHCP addresses, the cluster does not survive a host or daemon restart. Reboot the Mac and the nodes are gone; recreate takes about four minutes. Talos blocks in-place reboot in container mode anyway, so this is inherent to the substrate, not a provider bug. For ephemeral local development — spin up, test, tear down — it is a non-issue. If you need a cluster that survives reboots or exercises the full Talos lifecycle, the supported qemu provisioner is the right tool. The real fixes are persistent volumes and a static-IP option upstream; both are future work, not hidden costs.
What upstream said
I opened the conversation as a Discussion on siderolabs/talos, expecting to argue the merits. Andrey Smirnov — Talos’s lead maintainer — answered quickly and said no, for reasons that are worth more than a merge would have been:
- No macOS CI. They can’t test it where they test everything else, so it would rot.
- A platform-specific provider is a snowflake. One more thing to maintain that only ever runs on a sliver of machines.
- Container mode is a workaround. This is the sharp one, and he’s right. apple/container runs Talos in container mode — the same class as the docker provisioner. It does not do the disk-based install, the bootloader, the in-place upgrade, the reboot. QEMU is the only local provider that exercises the full Talos lifecycle, and that lifecycle is the whole point of Talos.
He’s correct on every count, and I conceded them. I had also leaned on some older networking issues to argue QEMU’s vmnet path was weak; he pointed out those are largely fixed. That removes most of my “why not QEMU” case. The honest residual benefit is narrow: apple/container is a no-Docker, per-node-kernel option for fast ephemeral dev on Apple Silicon — a sibling of the docker provisioner, not a rival to QEMU. Real, but not enough to justify upstream maintenance.
There’s a mistake buried in why I expected a yes. pkg/provision.Provisioner is a clean Go interface, and Go’s structural typing let me implement it from an out-of-tree repo and have it just compile. I read that cleanliness as an invitation. It isn’t one. An interface is an internal seam, not a public extension point. Talos exposes it to share one cluster- creation flow between their two providers — docker (fast, low-fidelity, for the volume of ephemeral clusters their CI burns through) and qemu (full-fidelity, for real boot and upgrade). There’s no plugin loader, no out-of-tree registry, no stability promise on that interface; they change it when they need to. “I can implement it” and “they will maintain it” are different sentences. I half-conflated them — which is a common contributor error, and worth naming.
The principle I actually walked into
The question that stuck with me afterwards: why is a Mac-native project content to run QEMU instead of Apple’s own runtime — the native son?
Because the native son belongs to macOS, not to Talos. For a cross-platform OS project, QEMU is the native son — it’s the thing that’s native to every environment Talos runs in:
- One codebase, all platforms. QEMU runs on Linux, macOS, Windows. Talos’s CI and real targets are Linux. With QEMU, the provider, the boot flow, the test harness are identical everywhere, and macOS is just “QEMU with HVF acceleration.” An Apple-only provider is a second implementation that can never run in their Linux CI.
- QEMU on Apple Silicon already runs on Apple’s hypervisor. It uses HVF (Hypervisor.framework) underneath — it’s hardware-accelerated by Apple’s own silicon. The marginal win from going fully Apple-native is boot polish, not capability.
- Less control where an OS needs the most. QEMU lets you define firmware, disk controllers, NICs, boot order — the things an OS cares about. Apple’s higher-level APIs give less; the container abstraction gives least.
This isn’t a Talos quirk. Lima, minikube, kind, Vagrant all lean on QEMU or a shared abstraction on macOS too, even though native is faster. For tooling maintainers, uniformity beats native-optimum — almost always.
So the spike didn’t merge, and that’s the right outcome. What it produced was sharper than a merge: a working provider that proves the runtime can host Talos, the DHCP insight that explains exactly why a native provider is the only clean way to do it, and a clear read on why the people who own the codebase rationally won’t. The interesting work was never the wrapper. It was tracing one DHCP packet to the place where it decides your architecture — and then learning where that architecture stops being worth it.
This site is the lab side of my work. The polished portfolio lives at binhsu.org.