A version number tripled my cloud bill — and only a machine caught it
I had seven guardrails against exactly this. Six were written rules. One was enforced by a machine — and it was the only one that fired.

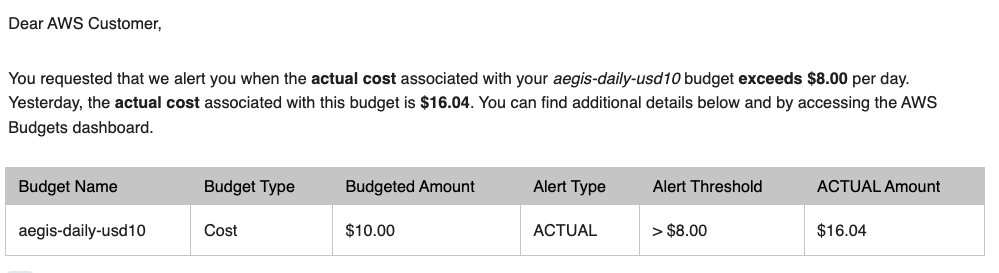
I know my FinOps. An empty Kubernetes cluster on AWS — control plane, zero nodes — runs under 20¢ an hour. So when a budget email told me I’d burned over $8 in a single day, I knew something was wrong.
The cause was almost funny. I’d spun up a cluster to test something, the setup half-failed and left it running, and three days later the teardown jammed too. So it sat there billing 24/7 — at 6× even the rate I expected, because the version I’d pinned had quietly aged out of support. A date had become a price.
But that’s not the part that stuck with me.
Here’s the part that did: I had seven guardrails against exactly this. Seven. And it still ran for three days — because six of them were rules I was supposed to follow, and only one, a budget alarm, was something a machine did on its own. Six good intentions, written down, all politely failed to fire. The one that caught it was the one I didn’t have to remember.
A written rule is a request. Enforcement is a guarantee.
The rest of this is the precise version — the numbers, the table, and the four fixes.
1. The cost driver was the extended-support surcharge, not usage
Amazon EKS gives each Kubernetes version ~14 months of standard support, then 12 months of extended support at an added charge. The numbers:
| Line item | $/hr per cluster |
|---|---|
| EKS control plane (standard support) | $0.10 |
| Extended-support surcharge | +$0.50 |
| What I was actually billed | $0.60 (6×) |
My pinned version had passed its end-of-standard-support date months earlier, so every apply produced an extended-support cluster. Over the window, 83% of the EKS spend was the surcharge — the base rate was a rounding error next to it. The cluster wasn’t expensive because it was big. It was expensive because of a date.
In a managed control plane, a version number is a price.
2. Almost every guardrail was operator-discipline; only the machine-enforced one fired
This is the part worth internalising. Guardrails split into two layers:
- Operator-discipline — written rules, conventions, “remember to destroy.” They depend on a human being present and doing the right thing.
- Machine-enforced — something acts with no human in the loop.
Here’s the full set, and which fired:
| Guardrail | Layer | Outcome |
|---|---|---|
| AWS Budgets alarm | machine-enforced | ✅ fired — caught it at ~$29 |
| Destroy partial stack on a failed apply | operator-discipline | ❌ not executed |
| Tear down after verify | operator-discipline | ❌ not executed |
| Apply-time cost estimate | operator-discipline | ❌ modelled the base rate, missed the 6× |
| CI green/red discipline | operator-discipline | ❌ a red pipeline carried no cost meaning |
| kyverno teardown robustness | operational | ❌ deadlocked the destroy |
| OIDC teardown access | machine, but mis-scoped | ⚠️ blocked the teardown |
Six of the seven needed me. The one that didn’t is the one that worked. Left to its monthly forecast the trajectory was ~$400 for a single test stack; the daily budget alarm bounded the loss to ~$29.
A written rule is a request. Enforcement is a guarantee.
3. A failed apply leaves billable orphans — and a failed destroy still bills
The cluster survived three days because the teardown itself deadlocked — an admission-webhook finalizer jammed kyverno’s uninstall before terraform ever reached the cluster resource. It’s tempting to think “delete” stops the meter. It doesn’t: a de-provisioning run that fails is not free, it bills until it actually finishes.
The dangerous state isn’t “down.” It’s “half-up, with nothing reconciling it.”
4. The fix is to lower the prose into enforcement
The remediation wasn’t “try harder to remember.” It was converting each written discipline into a control a machine enforces — making them all look like the budget alarm:
| Machine-enforced control | What it enforces | The written rule it replaces |
|---|---|---|
| TTL reaper | auto-destroys clusters past N hours | “remember to tear down” |
| Version gate (policy-as-code) | blocks an aged-out version at plan time | “estimate the cost right” |
| AWS Budget Actions | acts on breach, not just emails | “watch the bill” |
| Stop-hook | refuses to end a session with a cloud-mutating run unreconciled | “destroy the partial stack” |
They share one shape: default-deny, with an explicit human override and an audit trail. That shape is the whole lesson. The budget alarm worked because it watches the symptom — spend — and needs no prior knowledge that any particular resource exists. Everything else now joins it on the machine side of the line.
Don’t ask the system to behave. Make misbehaving structurally impossible.