The YouTube talk had no captions, so I built a transcriber
A local YouTube-to-text tool — captions when they exist, Whisper when they don't. Built to read one talk about working with AI agents.
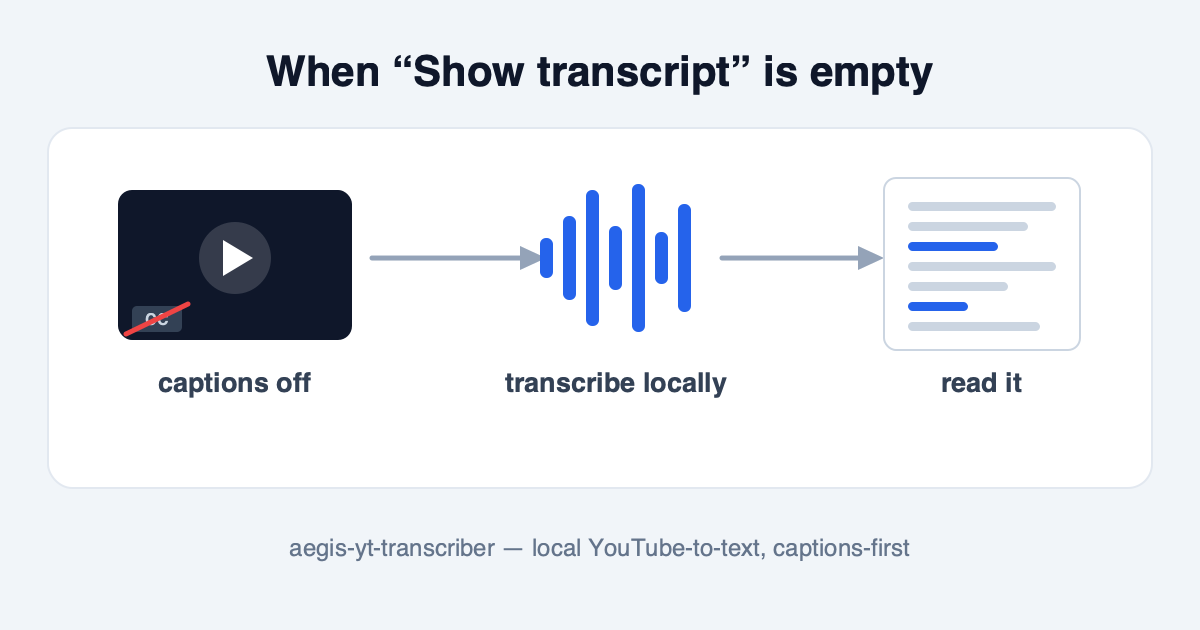
I wanted to read Beyond the basics with Claude Code, not watch it twice. It was Daisy Hollman’s YouTube talk about working with AI agents at scale — a good one. I’d watched it once; I wanted the text so I could pull quotes and think against it. I clicked Show transcript. Nothing. Captions were off.
So I did the obvious thing and built a small tool to turn the URL into text — aegis-yt-transcriber, MIT and on GitHub. There’s a loop here I enjoy: I used an agent to build a tool to read a talk about using agents. The tool is small. The story is in two design calls.
First call: where does the text come from?
My first instinct was the official YouTube Data API. It has a captions endpoint, so this should be a five-minute job. It isn’t. captions.download only works for videos you own — you authenticate as the uploader. There’s no official way to pull captions off an arbitrary public video. That’s deliberate, and it’s a wall.
I’ve hit this wall before: the official API is the front door, and the front door is locked for this. The route that works is the same timedtext track YouTube’s own player reads. yt-dlp already speaks it — --write-subs for human-written captions, --write-auto-subs for the auto-generated ones. It’s unofficial, so it can break when YouTube changes the player, but it’s the only thing that actually answers the question.
Second call: don’t transcribe what’s already written
Here’s the decision I’m happiest with. Most videos have captions — auto-generated if nothing else. Running speech-to-text on those would be burning a GPU to recreate text that already exists. So the default is captions-first:
1
2
3
4
5
captions? ── yes ─→ pull the caption track ──────────────────→ text (seconds)
│
no / disabled
↓
download audio → Whisper → text
“No usable captions” is a stricter test than the CC button being off. Toggling captions off in the player only hides a track that still exists on YouTube’s side — the tool pulls it anyway. The fallback fires only when the video publishes no track at all: no human captions, no auto-generated ones, nothing for yt-dlp to fetch. That’s the talk that started this — I clicked Show transcript and got an empty panel because there was genuinely no track behind it. Only then does it download the audio and run Whisper locally. Everything else gets the fast path for free.
That split is the whole point. The talk I was trying to read kept saying don’t pay for what you don’t use about context windows; it applies just as well to compute. If the text is sitting there, take it. Only spend the GPU when there’s no other way.
The fallback stays on your machine
When it does fall back, the audio goes to a local Whisper model — no third-party transcription service, nothing uploaded. On Apple Silicon it uses mlx-whisper (Metal-accelerated); on Windows and Linux it uses faster-whisper on CPU or GPU. The dependency that’s Apple-only is gated behind an environment marker, so pip/uv install the right backend per platform and skip the wrong one. The audio never leaves the laptop, which matters more for a private recording than for a public YouTube link — but it’s the same code either way.
Proving “cross-platform” instead of claiming it
“Runs everywhere” is easy to write and easy to be wrong about. The heavy dependencies are lazy-imported, so the unit tests need only pytest and no model downloads — which means CI can run them on Ubuntu, Windows, and macOS on every push. The cross-platform claim is a green check, not a sentence.
The tests themselves got a small discipline I’ve started using with agents: one agent wrote them, a separate agent reviewed them against the source, and only then did I run them. Author, reviewer, verifier — three contexts that don’t share a bias. It’s a cheap way to keep an agent from grading its own homework, and it’s the same “make clones of yourself” idea the talk was about, pointed at correctness instead of throughput.
The loop
The tool exists because a talk about working with agents had its captions turned off. It’s built with an agent, it’s tested by agents checking each other, and the first thing it transcribed was that talk. Small tool, but it earned its place — and it’ll be the first thing I reach for the next time Show transcript comes back empty.
Code (MIT, fork-friendly): github.com/BinHsu/aegis-yt-transcriber